The power of Revenue Marketing Analytics™ is its ability to take disparate data from myriad different sources, identify key performance indicators (KPI’s) and most relevant, actionable measures and metrics and – perhaps the most important part – present them in simple, easy to understand data visualizations.
Revenue Marketing paints pretty pictures from very messy, sometimes even ugly data. It takes complex, sophisticated analysis and tells a simple story.
There are a number of data visualization tools in the Revenue Marketer’s toolbox.
Graphs are perhaps the most common and useful tool. But how do you know which graph to use with which type of data? Do you understand the common pitfalls of different graph types? As we all know, a picture is worth a thousand words!
Let’s review some common, and some not-so-common, data graphing tools and best practices for using each type.
Bar Graphs
Bar graphs, or column graphs, can be used to measure different categories. The order of the columns on the x-axis can be in any order: largest to smallest, alphabetically or any order that makes sense.
Bar graphs generally are a better choice than pie charts to present snapshot distributions.
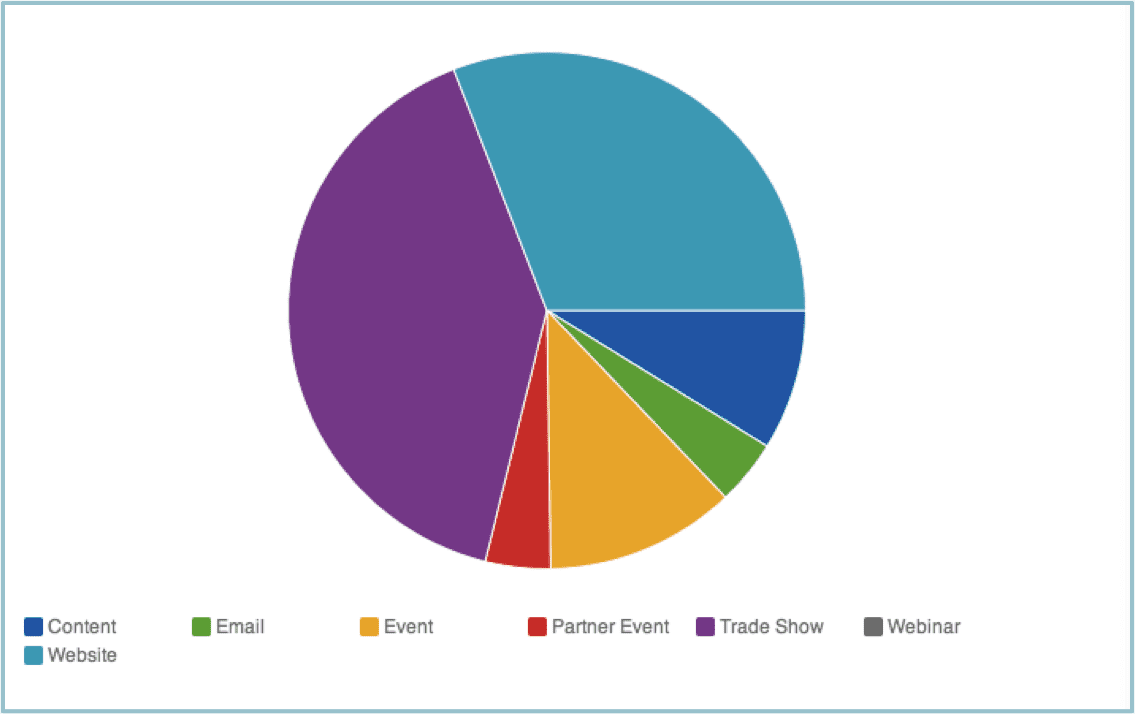
In the pie chart immediately below, it is difficult to tell whether there is more revenue from Content (blue slice) or Event (gold slice). It can be done, but it takes extra effort. Plus, there is no scale to help you gauge what dollar figure to attach to each slice without adding data labels that might clutter up the visualization.
First-Touch Revenue Attribution
In the bar graph visualization of the same data, shown below, it is immediately clear there is more revenue from Event than Content. Plus, the values on the y-axis (vertical axis) make clear the nominal figure of the revenue, in a visually obvious way.
First-Touch Revenue Attribution
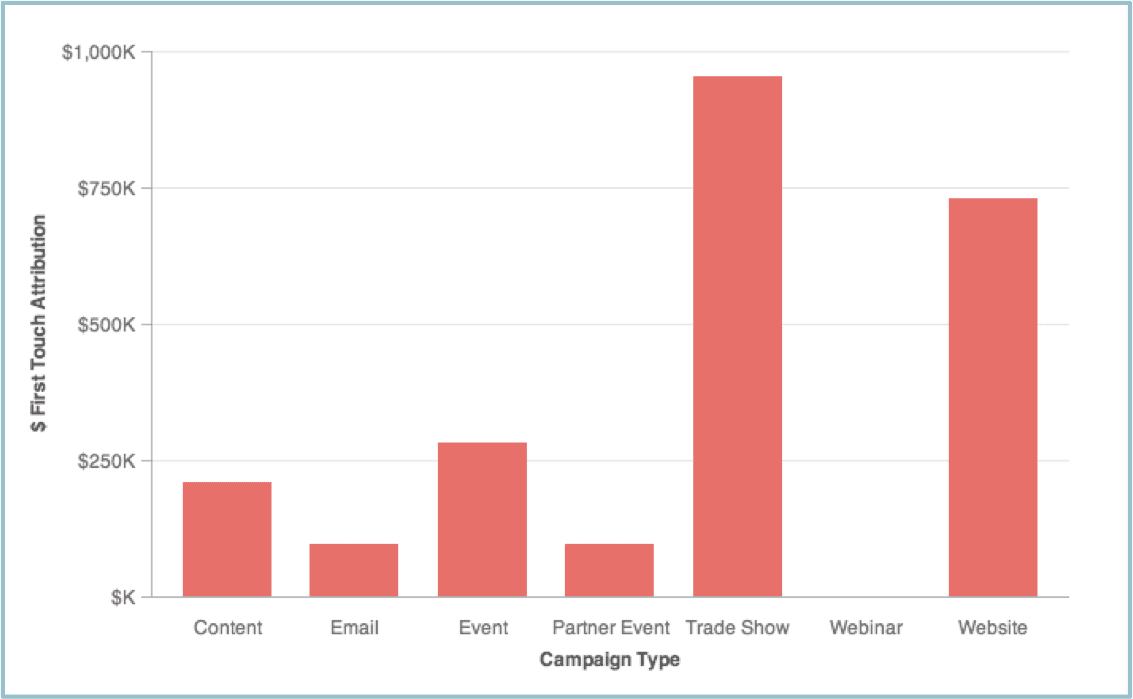
It is easier for our eyes to compare the height of the columns than it is for our eyes to gauge the relative size of the slices of a pie.
Bar graphs are also commonly used to compare things that change over time (as broadly as years, months or weeks). The increments are usually spaced equally apart, visualizing the data in a time-series.
Sales per month, visualized below, is a typical use of a bar graph.
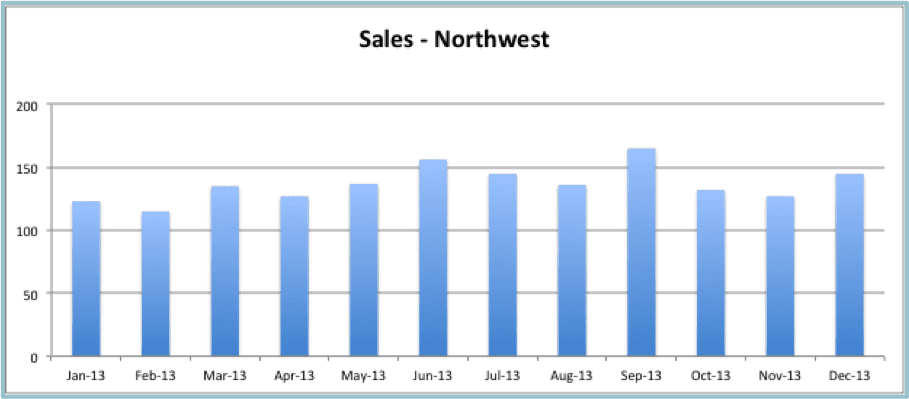
Major gridlines every 50 units make it easy to get a basic understanding of the sales each month and how the sales in each month compare to sales in other months.
Strictly speaking, a histogram should be used in this instance, but visually a column chart with a gap between each increment works well to present this kind of data.
Stacked Bar Graphs
Stacked bar graphs are a great way to add an extra level of detail to the metric in each increment. Stacked bar graphs are used to display multiple series of data together and make it easy to compare across categories. They have the dual benefit of displaying totals for each period in addition to visualizing comparisons within each period and across periods.
The stacked bar graph below displays two things: (1) total Northwest Sales in each month of the year and (2) total Northwest Sales by each Sales Associate in each month of the year.
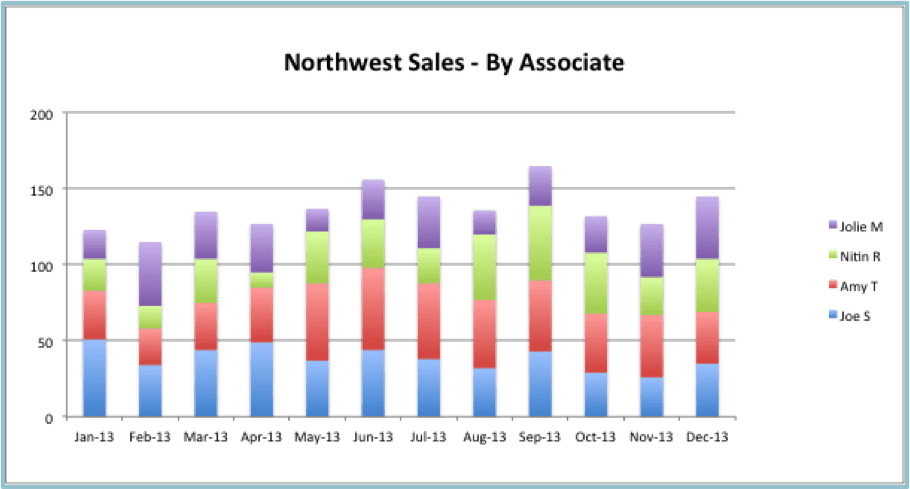
Stacked bar graphs work best if the segmentation isn’t too detailed. If there are too many segments in each column, the breakdown becomes difficult to understand.
Side-By-Side Bar Graphs
Side-by-side bar graphs can be used to compare two related categories in the same metric over the same period. The example below compares the percent of U.S. population that are never married, by gender, over a twenty-year time frame.
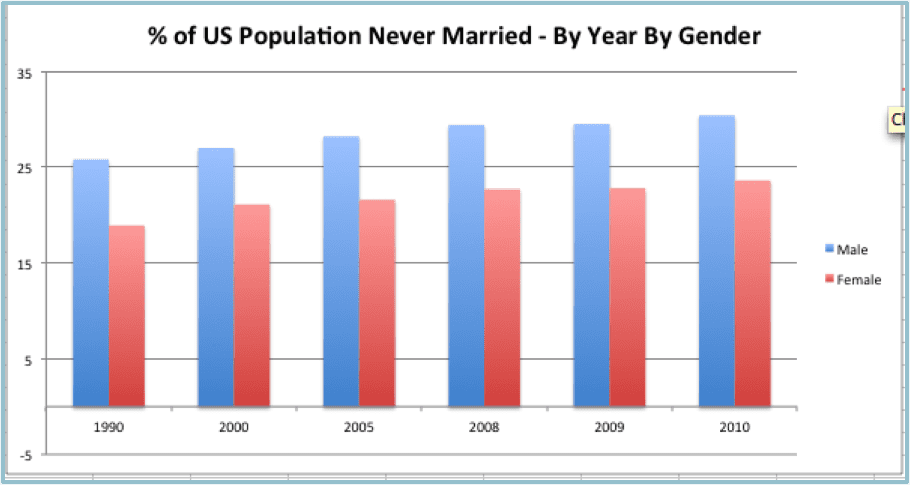
Side by side bar graphs work best when there are less than half a dozen or so elements being compared in each period.
Smart Tip: Bar Graphs versus Histograms
Histograms are often confused with bar graphs but histograms visualize continuous data, as in a time-series, or data that’s in a continuous distribution. Histograms don’t have gaps between the columns.
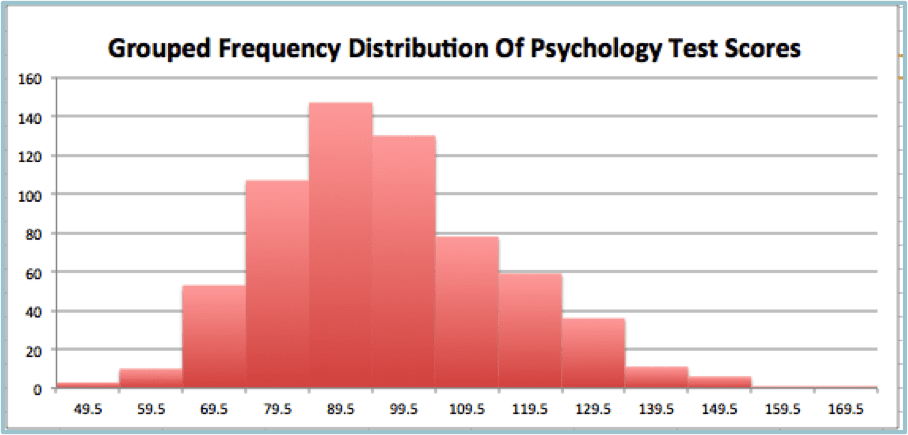
Histograms are a good choice to use when presenting distributions along a single metric of continuous data. In the example above, the data (the number of tests) is grouped into bins of ten-point ranges.
Bullet Graphs
Bullet graphs are a modification of bar graphs, invented by Stephen Few to replace the circular gauges and meters commonly used on dashboards with a graph that visualizes a richer data display, using much less space.
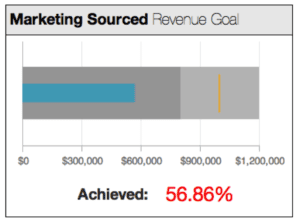
Bullet graphs have several key components. In the bullet graph above, the teal bar graph indicates the performance measure of marketing-sourced revenue during the period. The short gold vertical bar displays the revenue goal target measure. The sub-head in red indicates the percentage of the goal achieved.
Stacked bars are an important part of bullet graphs, with different shades of background fill that encode qualitative measures like bad, satisfactory and good.
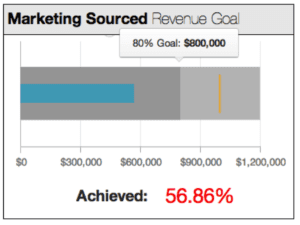
The bullet graph above contains a stacked bar graph. The dark gray bar indicates 80% of the goal while the light gray bar indicates 120% of the goal.
The technical specification for bullet graphs, written by Stephen Few, is here: https://www.perceptualedge.com/articles/misc/Bullet_Graph_Design_Spec.pdf
Scatter Plots
Scatter Plots are used to show the relationship between two variables. One variable is plotted on the x-axis and another is plotted on the y-axis. X-Y scatter plots can be used to graphically suggest whether there is a cause and effect relationship based on how strong the correlation is.
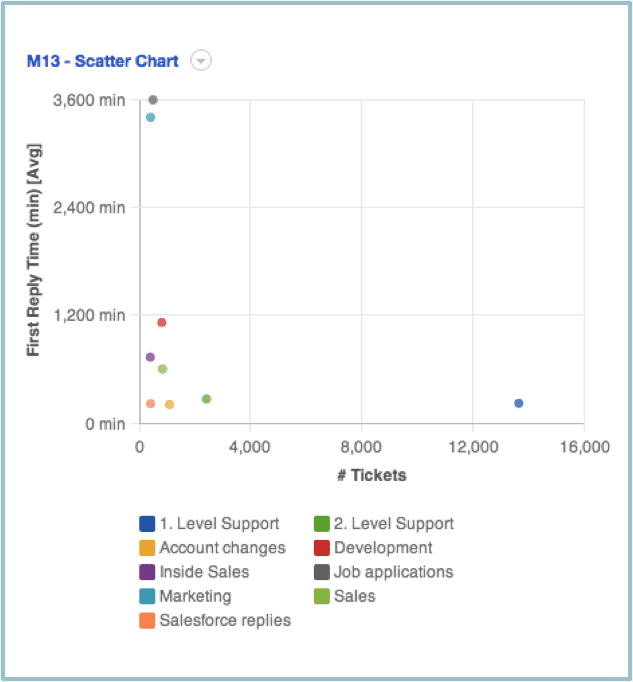
In the scatter plot above, it is clear that there are many more Level 1 Support tickets than other types since the blue dot is far to the right (the high end) on the horizontal axis. At the same time, average time required to reply to Level 1 Support tickets is relatively low, as indicated by its plotting at the low end of the vertical axis. There are relatively few Marketing and Job Application tickets and their response times are much longer than other types of tickets.
Interactive Graphs and Mouse Overs
Additional information can be embedded in graphs only a mouse-over away. The color differences between some of the data points plotted above is subtle. Mouse over each data point, however, and Meta data information can be revealed, as in the example below.
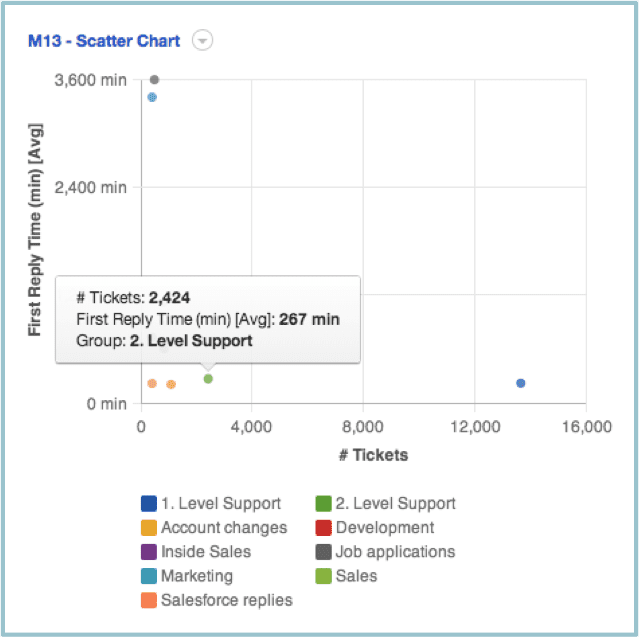
If every data point displayed its label simultaneously, the visualization would be very busy and cluttered. Indeed, the location of many data points plotted on the graph would be concealed, defeating the purpose of the scatter plot itself! So user driven interactivity really improves the visualization of the data.
Another example of great usability is to make the legend interactive. Mouse over each item in the legend and the other ticket types are grayed out. This makes the particular ticket type under the pointer rise into the foreground.
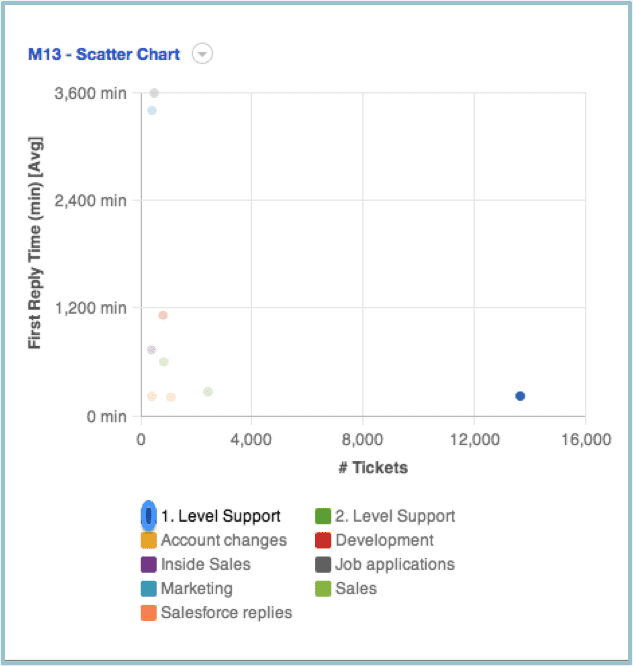
Notice how the other data points in the plot are also minimized via increased transparency. This makes it easy to quickly identify the particular location in the plot of each item you mouse over in the legend.
Scatter plots are also great tools for determining whether you should conduct a cluster analysis. If groups of data points are in different clusters in several different areas of the plot, a cluster analysis can help you understand what attributes are common to each group of data points and which combination of attributes are relatively unique to each particular cluster. This can be a great aid in classifying and targeting sales prospects, to cite one common usage.
So, What Next?
- Want to dive deeper in reporting? Check out our Excel for Marketers on-demand class
- Enroll in the free Revenue Marketing Basics class to start tying your reporting to bottom-line numbers that matter!
- Send us any questions you may have!